martes, 20 de junio de 2017
miércoles, 16 de mayo de 2012
USO DE SESIONES
El uso de sesiones nos proporciona una forma fácil de guardar datos del usuario sin tener que recurrir a mysql o archivos de texto plano, claro está, de forma temporal. Con sesiones se puede realizar:
- Saber si un usuario a ingresado en el a través de login.
- Cambio de Hoja de estilos CSS por parte del usuario.
- Cualquier cosa que requiera una variable temporal en relación a la visita del usuario.
Las sesiones se crean de forma bastante sencilla:
session_start();
?>
A través de esto crearemos una sesión. OJO: Para poder usar la variables de sesión creadas hay que colocar esto al principio de nuestro script en PHP antes de cualquier sentencia HTML o generará un error.
Para definir una variable de sesión (que se guarda de manera temporal, usaremos lo siguiente:
if (isset ($_SESSION["variable"] {
echo "Usted ha introducido la variable $_SESSION["variable"]
} else {
//Remitente de datos (Index.php)
?>
//Receptor de datos (capturador.php)
session_start();
$_POST["nombre"] = $_SESSION["variable"]; ?>
Con ese script lo que realizamos es lo siguiente:
- Colocamos un IF en el index y si no existe damos un formulario para crearla.
- En el capturador recibimos los datos y definimos variable de sesión.
- Con el código javascript redireccionamos al index sin alterar el PHP.
Como ves es bastante sencillo, ahora solo nos falta borrar esa sesión:
session_start();
session_destroy();
header("Location: index.php");
?>
Podríamos definir una variable de sesión para un estilo css, seleccionado mediante un form.
En el siguiente tutorial sobre el uso de sesiones enseñaré a hacer con ellas un sistema para modificar páginas php con contraseña para mantener actualizado el sitio web sin MYSQL.
lunes, 19 de diciembre de 2011
ODBC
Open DataBase Connectivity (ODBC) es un estándar de acceso a bases de datos desarrollado por SQL Access Group en 1992, el objetivo de ODBC es hacer posible el acceder a cualquier dato desde cualquier aplicación, sin importar qué sistema de gestión de bases de datos (DBMS) almacene los datos, ODBC logra esto al insertar una capa intermedia (CLI) denominada nivel de Interfaz de Cliente SQL, entre la aplicación y el DBMS, el propósito de esta capa es traducir las consultas de datos de la aplicación en comandos que el DBMS entienda. Para que esto funcione tanto la aplicación como el DBMS deben ser compatibles con ODBC, esto es que la aplicación debe ser capaz de producir comandos ODBC y el DBMS debe ser capaz de responder a ellos. Desde la versión 2.0 el estándar soporta SAG y SQL.
El software funciona de dos modos, con un software manejador en el cliente, o una filosofía cliente-servidor. En el primer modo, el driver interpreta las conexiones y llamadas SQL y las traduce desde el API ODBC hacia el DBMS. En el segundo modo para conectarse a la base de datos se crea una DSN dentro del ODBC que define los parámetros, ruta y características de la conexión según los datos que solicite el creador o fabricante.
*Configurar un origen de datos ODBC
Antes de que pueda crear vistas remotas o usar un paso a través de SQL, tiene que instalar un controlador ODBC y configurar el origen de datos ODBC.
Elegir un controlador ODBC
Para instalar los controladores ODBC para estos tipos de datos, use el programa de instalación de Visual FoxPro. Si elige la opción de instalación Completa, se instalan todos los controladores.
Cuando haya elegido un controlador, puede usar el origen de datos predeterminado o agregar un origen de datos ODBC.
Para agregar un origen de datos ODBC
Elija el icono Herramientas administrativas en el Panel de control de Windows.
Elija el acceso directo Orígenes de datos ODBC.
En el cuadro de diálogo Administrador de orígenes de datos ODBC, haga clic en Agregar y, a continuación, seleccione el controlador que desee en la lista Controladores ODBC instalados y elija Aceptar.
En el cuadro de diálogo Configuración de ODBC, establezca los valores de las opciones conforme sea necesario y elija Aceptar.
Para obtener información acerca de cómo configurar un origen de datos específico del controlador elegido, elija el botón Ayuda en el cuadro de diálogo Configuración de ODBC.
Instalar orígenes de datos ODBC
Puede obtener soporte para Conectividad abierta de bases de datos (ODBC) si elige la opción de instalación Completa o Personalizada. Con ODBC, puede tener acceso a un origen de datos SQL Server desde Visual FoxPro; sin embargo, antes de tener acceso al origen de datos, deberá definirlo.
Para definir un origen de datos
Cambie al Panel de control de Windows y elija el icono ODBC.
En el cuadro de diálogo Orígenes de datos, elija Agregar.
En el cuadro de diálogo Agregar origen de datos, seleccione el controlador ODBC SQL Server y elija Aceptar.
En el cuadro de diálogo Instalación de ODBC SQL Server, escriba el nombre, la descripción y cualquier otra información del origen de datos y, a continuación, elija Aceptar.
En el cuadro de diálogo Orígenes de datos, elija Cerrar.
El software funciona de dos modos, con un software manejador en el cliente, o una filosofía cliente-servidor. En el primer modo, el driver interpreta las conexiones y llamadas SQL y las traduce desde el API ODBC hacia el DBMS. En el segundo modo para conectarse a la base de datos se crea una DSN dentro del ODBC que define los parámetros, ruta y características de la conexión según los datos que solicite el creador o fabricante.
*Configurar un origen de datos ODBC
Antes de que pueda crear vistas remotas o usar un paso a través de SQL, tiene que instalar un controlador ODBC y configurar el origen de datos ODBC.
Elegir un controlador ODBC
Para instalar los controladores ODBC para estos tipos de datos, use el programa de instalación de Visual FoxPro. Si elige la opción de instalación Completa, se instalan todos los controladores.
Cuando haya elegido un controlador, puede usar el origen de datos predeterminado o agregar un origen de datos ODBC.
Para agregar un origen de datos ODBC
Elija el icono Herramientas administrativas en el Panel de control de Windows.
Elija el acceso directo Orígenes de datos ODBC.
En el cuadro de diálogo Administrador de orígenes de datos ODBC, haga clic en Agregar y, a continuación, seleccione el controlador que desee en la lista Controladores ODBC instalados y elija Aceptar.
En el cuadro de diálogo Configuración de ODBC, establezca los valores de las opciones conforme sea necesario y elija Aceptar.
Para obtener información acerca de cómo configurar un origen de datos específico del controlador elegido, elija el botón Ayuda en el cuadro de diálogo Configuración de ODBC.
Instalar orígenes de datos ODBC
Puede obtener soporte para Conectividad abierta de bases de datos (ODBC) si elige la opción de instalación Completa o Personalizada. Con ODBC, puede tener acceso a un origen de datos SQL Server desde Visual FoxPro; sin embargo, antes de tener acceso al origen de datos, deberá definirlo.
Para definir un origen de datos
Cambie al Panel de control de Windows y elija el icono ODBC.
En el cuadro de diálogo Orígenes de datos, elija Agregar.
En el cuadro de diálogo Agregar origen de datos, seleccione el controlador ODBC SQL Server y elija Aceptar.
En el cuadro de diálogo Instalación de ODBC SQL Server, escriba el nombre, la descripción y cualquier otra información del origen de datos y, a continuación, elija Aceptar.
En el cuadro de diálogo Orígenes de datos, elija Cerrar.
INTRODUCCIÓN A LAS HERRAMIENTAS CASE
1. Introducción.
Las Herramientas case es la mejor base para el proceso de análisis y desarrollo de software, así que las computadoras afectan nuestras vidas nos guste o no. Utilizamos las maquinas en nuestra vida diaria, la mayor parte del tiempo sin reconocer conscientemente que estamos haciéndolo, a diario utilizamos aplicaciones domésticas como microondas, televisión, vídeo Casseteras o en la calle los cajeros automáticos, entre otros.
La verdad es que no podemos escapar de las computadoras. El rápido incremento es una hazaña de las computadoras junto al dramático decremento en tamaño y costo, y así esta tecnología, es una larga variedad de aplicaciones que éstas pueden soportar.
Desde el inicio de la escritura de software, ha existido un conocimiento de la necesidad de herramientas automatizadas para ayudar al diseñador del software. Inicialmente, la concentración estaba en herramientas de apoyo a programas como traductores, recopiladores, ensambladores, procesadores de macros, montadores y cargadores. Este conjunto de aplicaciones, aumentó de una manera rápida en un breve espacio de tiempo, causando una gran demanda por nuevo software a desarrollar. A medida que se escribía nuevo software, habían ya en existencia millones y millones de líneas de código que necesitaban se mantenidas y actualizadas.
Significado sigla CASE
Computer
Aided Assisted Automated
Software Systems
Engineering
2. Qué son las Herramientas CASE?
Se puede definir a las Herramientas CASE como un conjunto de programas y ayudas que dan asistencia a los analistas, ingenieros de software y desarrolladores, durante todos los pasos del Ciclo de Vida de desarrollo de un Software (Investigación Preliminar, Análisis, Diseño, Implementación e Instalación.).
CASE es también definido como el Conjunto de métodos, utilidades y técnicas que facilitan el mejoramiento del ciclo de vida del desarrollo de sistemas de información, completamente o en alguna de sus fases.
Se puede ver al CASE como la unión de las herramientas automáticas de software y las metodologías de desarrollo de software formales.
Existe también el CASE integrado que fue comenzando a tener un impacto muy Significativo en los negocios y sistemas de información de las organizaciones, además con este CASE integrado las compañías pueden desarrollar rápidamente sistemas de mejor calidad para soportar procesos críticos del negocio y asistir en el desarrollo y promoción intensiva de la información de productos y servicios.
*ERwin:
PLATINUM ERwin es una herramienta para el diseño de base de datos, que Brinda productividad en su diseño, generación, y mantenimiento de aplicaciones. Desde un modelo lógico de los requerimientos de información, hasta el modelo físico perfeccionado para las características específicas de la base de datos diseñada, además ERwin permite visualizar la estructura, los elementos importantes, y optimizar el diseño de la base de datos. Genera automáticamente las tablas y miles de líneas de stored procedure y triggers para los principales tipos de base de datos.
ERwin hace fácil el diseño de una base de datos. Los diseñadores de bases de datos sólo apuntan y pulsan un botón para crear un gráfico del modelo E-R (Entidad _ relación) de todos sus requerimientos de datos y capturar las reglas de negocio en un modelo lógico, mostrando todas las entidades, atributos, relaciones, y llaves importantes.
La migración automática garantiza la integridad referencial de la base de datos. ERwin establece una conexión entre una base de datos diseñada y una base de datos, permitiendo transferencia entre ambas y la aplicación de ingeniería reversa. Usando esta conexión, ERwin genera automáticamente tablas, vistas, índices, reglas de integridad referencial (llaves primarias, llaves foráneas), valores por defecto y restricciones de campos y dominios.
ERwin soporta principalmente bases de datos relacionales SQL y bases de datos que incluyen Oracle, Microsoft SQL Server, Sybase. El mismo modelo puede ser usado para generar múltiples bases de datos, o convertir una aplicación de una plataforma de base de datos a otra.
*PowerDesigner
PowerDesigner, la herramienta de modelamiento número uno de la industria, permite a las empresas, de manera más fácil, visualizar, analizar y manipular metadatos, logrando un efectiva arquitectura empresarial de información.
PowerDesigner para Arquitectura Empresarial también brinda un enfoque basado en modelos, el cual permite alinear al negocio con la tecnología de información, facilitando la implementación de arquitecturas efectivas de información empresarial. Brinda potentes técnicas de análisis, diseño y gestión de metadatos a la empresa.
PowerDesigner combina varias técnicas estándar de modelamiento con herramientas líder de desarrollo, como .NET, Sybase WorkSpace, Sybase Powerbuilder, Java y Eclipse, para darle a las empresas soluciones de análisis de negocio y de diseño formal de base de datos. Además trabaja con más de 60 bases de datos relacionales.
Las Herramientas case es la mejor base para el proceso de análisis y desarrollo de software, así que las computadoras afectan nuestras vidas nos guste o no. Utilizamos las maquinas en nuestra vida diaria, la mayor parte del tiempo sin reconocer conscientemente que estamos haciéndolo, a diario utilizamos aplicaciones domésticas como microondas, televisión, vídeo Casseteras o en la calle los cajeros automáticos, entre otros.
La verdad es que no podemos escapar de las computadoras. El rápido incremento es una hazaña de las computadoras junto al dramático decremento en tamaño y costo, y así esta tecnología, es una larga variedad de aplicaciones que éstas pueden soportar.
Desde el inicio de la escritura de software, ha existido un conocimiento de la necesidad de herramientas automatizadas para ayudar al diseñador del software. Inicialmente, la concentración estaba en herramientas de apoyo a programas como traductores, recopiladores, ensambladores, procesadores de macros, montadores y cargadores. Este conjunto de aplicaciones, aumentó de una manera rápida en un breve espacio de tiempo, causando una gran demanda por nuevo software a desarrollar. A medida que se escribía nuevo software, habían ya en existencia millones y millones de líneas de código que necesitaban se mantenidas y actualizadas.
Significado sigla CASE
Computer
Aided Assisted Automated
Software Systems
Engineering
2. Qué son las Herramientas CASE?
Se puede definir a las Herramientas CASE como un conjunto de programas y ayudas que dan asistencia a los analistas, ingenieros de software y desarrolladores, durante todos los pasos del Ciclo de Vida de desarrollo de un Software (Investigación Preliminar, Análisis, Diseño, Implementación e Instalación.).
CASE es también definido como el Conjunto de métodos, utilidades y técnicas que facilitan el mejoramiento del ciclo de vida del desarrollo de sistemas de información, completamente o en alguna de sus fases.
Se puede ver al CASE como la unión de las herramientas automáticas de software y las metodologías de desarrollo de software formales.
Existe también el CASE integrado que fue comenzando a tener un impacto muy Significativo en los negocios y sistemas de información de las organizaciones, además con este CASE integrado las compañías pueden desarrollar rápidamente sistemas de mejor calidad para soportar procesos críticos del negocio y asistir en el desarrollo y promoción intensiva de la información de productos y servicios.
*ERwin:
PLATINUM ERwin es una herramienta para el diseño de base de datos, que Brinda productividad en su diseño, generación, y mantenimiento de aplicaciones. Desde un modelo lógico de los requerimientos de información, hasta el modelo físico perfeccionado para las características específicas de la base de datos diseñada, además ERwin permite visualizar la estructura, los elementos importantes, y optimizar el diseño de la base de datos. Genera automáticamente las tablas y miles de líneas de stored procedure y triggers para los principales tipos de base de datos.
ERwin hace fácil el diseño de una base de datos. Los diseñadores de bases de datos sólo apuntan y pulsan un botón para crear un gráfico del modelo E-R (Entidad _ relación) de todos sus requerimientos de datos y capturar las reglas de negocio en un modelo lógico, mostrando todas las entidades, atributos, relaciones, y llaves importantes.
La migración automática garantiza la integridad referencial de la base de datos. ERwin establece una conexión entre una base de datos diseñada y una base de datos, permitiendo transferencia entre ambas y la aplicación de ingeniería reversa. Usando esta conexión, ERwin genera automáticamente tablas, vistas, índices, reglas de integridad referencial (llaves primarias, llaves foráneas), valores por defecto y restricciones de campos y dominios.
ERwin soporta principalmente bases de datos relacionales SQL y bases de datos que incluyen Oracle, Microsoft SQL Server, Sybase. El mismo modelo puede ser usado para generar múltiples bases de datos, o convertir una aplicación de una plataforma de base de datos a otra.
*PowerDesigner
PowerDesigner, la herramienta de modelamiento número uno de la industria, permite a las empresas, de manera más fácil, visualizar, analizar y manipular metadatos, logrando un efectiva arquitectura empresarial de información.
PowerDesigner para Arquitectura Empresarial también brinda un enfoque basado en modelos, el cual permite alinear al negocio con la tecnología de información, facilitando la implementación de arquitecturas efectivas de información empresarial. Brinda potentes técnicas de análisis, diseño y gestión de metadatos a la empresa.
PowerDesigner combina varias técnicas estándar de modelamiento con herramientas líder de desarrollo, como .NET, Sybase WorkSpace, Sybase Powerbuilder, Java y Eclipse, para darle a las empresas soluciones de análisis de negocio y de diseño formal de base de datos. Además trabaja con más de 60 bases de datos relacionales.
domingo, 18 de diciembre de 2011
NORMALIZACIÓN II
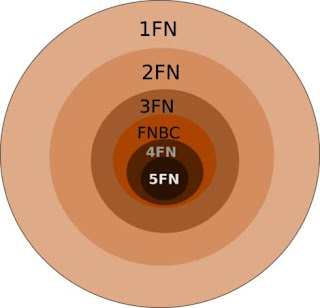
* Cuarta Forma Normal (4FN)
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X→→Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.
* Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si: • La tabla esta en 4FN • No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que esta en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X→→Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.
* Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si: • La tabla esta en 4FN • No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que esta en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
NORMALIZACIÓN I
¿Qué es normalización?
Normalización es un proceso que clasifica relaciones, objetos, formas de relación y demás elementos en grupos, en base a las características que cada uno posee. Si se identifican ciertas reglas, se aplica un categoría; si se definen otras reglas, se aplicará otra categoría.
Estamos interesados en particular en la clasificación de las relaciones BDR. La forma de efectuar esto es a través de los tipos de dependencias que podemos determinar dentro de la relación. Cuando las reglas de clasificación sean más y más restrictivas, diremos que la relación está en una forma normal más elevada. La relación que está en la forma normal más elevada posible es que mejor se adapta a nuestras necesidades debido a que optimiza las condiciones que son de importancia para nosotros:
• La cantidad de espacio requerido para almacenar los datos es la menor
posible;
• La facilidad para actualizar la relación es la mayor posible;
• La explicación de la base de datos es la más sencilla posible.
Normalización es un proceso que clasifica relaciones, objetos, formas de relación y demás elementos en grupos, en base a las características que cada uno posee. Si se identifican ciertas reglas, se aplica un categoría; si se definen otras reglas, se aplicará otra categoría.
Estamos interesados en particular en la clasificación de las relaciones BDR. La forma de efectuar esto es a través de los tipos de dependencias que podemos determinar dentro de la relación. Cuando las reglas de clasificación sean más y más restrictivas, diremos que la relación está en una forma normal más elevada. La relación que está en la forma normal más elevada posible es que mejor se adapta a nuestras necesidades debido a que optimiza las condiciones que son de importancia para nosotros:
• La cantidad de espacio requerido para almacenar los datos es la menor
posible;
• La facilidad para actualizar la relación es la mayor posible;
• La explicación de la base de datos es la más sencilla posible.

TEORÍA DE NORMALIZACIÓN
Se aplica a los datos; con la finalidad de diseñar una base de datos más eficiente... Es un proceso que se basa en la descomposición aplicando las tres formas normales. 1FN, 2FN,·3FN.
En la 1FN , se busca eliminar los grupos repetitivos, logrando eliminar la redundancia de los datos
2FN, Todos los atributos deben depender completa y funcionalmente de la clave
3FN. Eliminar dependencias transitivas entre atributos no claves y eliminar campos que son resultados de càlculos de otros campos.
DICCIONARIO DE DATOS
Un diccionario de datos es un conjunto de metadatos que contiene las características lógicas y puntuales de los datos que se van a utilizar en el sistema que se programa, incluyendo nombre, descripción, alias, contenido y organización.
Identifica los procesos donde se emplean los datos y los sitios donde se necesita el acceso inmediato a la información, se desarrolla durante el análisis de flujo de datos y auxilia a los analistas que participan en la determinación de los requerimientos del sistema, su contenido también se emplea durante el diseño.
En un diccionario de datos se encuentra la lista de todos los elementos que forman parte del flujo de datos de todo el sistema. Los elementos mas importantes son flujos de datos, almacenes de datos y procesos. El diccionario de datos guarda los detalles y descripción de todos estos elementos.
PRIMERA FORMA NORMAL 1FN
Una tabla está en 1FN si sus atributos contienen valores atómicos. En el ejemplo, podemos ver que el atributo emails puede contener más de un valor, por lo que viola 1FN.
En general, tenemos una relación R con clave primaria K. Si un atributo M viola la condición de 1FN, tenemos dos opciones.
*Solución 1: duplicar los registros con valores repetidos
*Solución 2: separar el atributo que viola 1FN en una tabla
SEGUNDA FORMA NORMAL 2FN
Un esquema está en 2FN si:
Está en 1FN.
Todos sus atributos que no son de la clave principal tienen dependencia funcional completa respecto de todas las claves existentes en el esquema. En otras palabras, para determinar cada atributo no clave se necesita la clave primaria completa, no vale con una subclave.
La 2FN se aplica a las relaciones que tienen claves primarias compuestas por dos o más atributos. Si una relación está en 1FN y su clave primaria es simple (tiene un solo atributo), entonces también está en 2FN. Por tanto, de las soluciones anteriores, la tabla EMPLEADOS'(b) está en 1FN (y la tabla EMAILS no tiene atributos no clave), por lo que el esquema está en 2FN. Sin embargo, tenemos que examinar las dependencias funcionales de los atributos no clave de EMPLEADOS'(a). Las dependencias funcionales que tenemos son las siguientes:
nss->nombre, salario, email
puesto->salario
Como la clave es (nss, email), las dependencias de nombre, salario y email son incompletas, por lo que la relación no está en 2FN.
En general, tendremos que observar los atributos no clave que dependan de parte de la clave.
Para solucionar este problema, tenemos que hacer lo siguiente para los gupos de atributos con dependencia incompleta M:
Eliminar de R el atributo M.
Crear una nueva relación N con el atributo M y la parte de la clave primaria K de la que depende, que llamaremos K'.
La clave primaria de la nueva relación será K'.
TERCERA FORMA NORMAL 3FN
Una relación está en tercera forma normal si, y sólo si:
está en 2FN
y, además, cada atributo que no está incluido en la clave primaria no depende transitivamente de la clave primaria.
Por lo tanto, a partir de un esquema en 2FN, tenemos que buscar dependencias funcionales entre atributos que no estén en la clave.
En general, tenemos que buscar dependencias transitivas de la clave, es decir, secuencias de dependencias como la siguiente: K->A y A->B, donde A y B no pertenecen a la clave. La solución a este tipo de dependencias está en separar en una tabla adicional N el/los atributos B, y poner como clave primaria de N el atributo que define la transitividad A.
Siguiendo el ejemplo anterior, podemos detectar la siguiente transitividad:
nss->puesto
puesto->salario
En la 1FN , se busca eliminar los grupos repetitivos, logrando eliminar la redundancia de los datos
2FN, Todos los atributos deben depender completa y funcionalmente de la clave
3FN. Eliminar dependencias transitivas entre atributos no claves y eliminar campos que son resultados de càlculos de otros campos.
DICCIONARIO DE DATOS
Un diccionario de datos es un conjunto de metadatos que contiene las características lógicas y puntuales de los datos que se van a utilizar en el sistema que se programa, incluyendo nombre, descripción, alias, contenido y organización.
Identifica los procesos donde se emplean los datos y los sitios donde se necesita el acceso inmediato a la información, se desarrolla durante el análisis de flujo de datos y auxilia a los analistas que participan en la determinación de los requerimientos del sistema, su contenido también se emplea durante el diseño.
En un diccionario de datos se encuentra la lista de todos los elementos que forman parte del flujo de datos de todo el sistema. Los elementos mas importantes son flujos de datos, almacenes de datos y procesos. El diccionario de datos guarda los detalles y descripción de todos estos elementos.
PRIMERA FORMA NORMAL 1FN
Una tabla está en 1FN si sus atributos contienen valores atómicos. En el ejemplo, podemos ver que el atributo emails puede contener más de un valor, por lo que viola 1FN.
En general, tenemos una relación R con clave primaria K. Si un atributo M viola la condición de 1FN, tenemos dos opciones.
*Solución 1: duplicar los registros con valores repetidos
*Solución 2: separar el atributo que viola 1FN en una tabla
SEGUNDA FORMA NORMAL 2FN
Un esquema está en 2FN si:
Está en 1FN.
Todos sus atributos que no son de la clave principal tienen dependencia funcional completa respecto de todas las claves existentes en el esquema. En otras palabras, para determinar cada atributo no clave se necesita la clave primaria completa, no vale con una subclave.
La 2FN se aplica a las relaciones que tienen claves primarias compuestas por dos o más atributos. Si una relación está en 1FN y su clave primaria es simple (tiene un solo atributo), entonces también está en 2FN. Por tanto, de las soluciones anteriores, la tabla EMPLEADOS'(b) está en 1FN (y la tabla EMAILS no tiene atributos no clave), por lo que el esquema está en 2FN. Sin embargo, tenemos que examinar las dependencias funcionales de los atributos no clave de EMPLEADOS'(a). Las dependencias funcionales que tenemos son las siguientes:
nss->nombre, salario, email
puesto->salario
Como la clave es (nss, email), las dependencias de nombre, salario y email son incompletas, por lo que la relación no está en 2FN.
En general, tendremos que observar los atributos no clave que dependan de parte de la clave.
Para solucionar este problema, tenemos que hacer lo siguiente para los gupos de atributos con dependencia incompleta M:
Eliminar de R el atributo M.
Crear una nueva relación N con el atributo M y la parte de la clave primaria K de la que depende, que llamaremos K'.
La clave primaria de la nueva relación será K'.
TERCERA FORMA NORMAL 3FN
Una relación está en tercera forma normal si, y sólo si:
está en 2FN
y, además, cada atributo que no está incluido en la clave primaria no depende transitivamente de la clave primaria.
Por lo tanto, a partir de un esquema en 2FN, tenemos que buscar dependencias funcionales entre atributos que no estén en la clave.
En general, tenemos que buscar dependencias transitivas de la clave, es decir, secuencias de dependencias como la siguiente: K->A y A->B, donde A y B no pertenecen a la clave. La solución a este tipo de dependencias está en separar en una tabla adicional N el/los atributos B, y poner como clave primaria de N el atributo que define la transitividad A.
Siguiendo el ejemplo anterior, podemos detectar la siguiente transitividad:
nss->puesto
puesto->salario
Suscribirse a:
Comentarios (Atom)