Open DataBase Connectivity (ODBC) es un estándar de acceso a bases de datos desarrollado por SQL Access Group en 1992, el objetivo de ODBC es hacer posible el acceder a cualquier dato desde cualquier aplicación, sin importar qué sistema de gestión de bases de datos (DBMS) almacene los datos, ODBC logra esto al insertar una capa intermedia (CLI) denominada nivel de Interfaz de Cliente SQL, entre la aplicación y el DBMS, el propósito de esta capa es traducir las consultas de datos de la aplicación en comandos que el DBMS entienda. Para que esto funcione tanto la aplicación como el DBMS deben ser compatibles con ODBC, esto es que la aplicación debe ser capaz de producir comandos ODBC y el DBMS debe ser capaz de responder a ellos. Desde la versión 2.0 el estándar soporta SAG y SQL.
El software funciona de dos modos, con un software manejador en el cliente, o una filosofía cliente-servidor. En el primer modo, el driver interpreta las conexiones y llamadas SQL y las traduce desde el API ODBC hacia el DBMS. En el segundo modo para conectarse a la base de datos se crea una DSN dentro del ODBC que define los parámetros, ruta y características de la conexión según los datos que solicite el creador o fabricante.
*Configurar un origen de datos ODBC
Antes de que pueda crear vistas remotas o usar un paso a través de SQL, tiene que instalar un controlador ODBC y configurar el origen de datos ODBC.
Elegir un controlador ODBC
Para instalar los controladores ODBC para estos tipos de datos, use el programa de instalación de Visual FoxPro. Si elige la opción de instalación Completa, se instalan todos los controladores.
Cuando haya elegido un controlador, puede usar el origen de datos predeterminado o agregar un origen de datos ODBC.
Para agregar un origen de datos ODBC
Elija el icono Herramientas administrativas en el Panel de control de Windows.
Elija el acceso directo Orígenes de datos ODBC.
En el cuadro de diálogo Administrador de orígenes de datos ODBC, haga clic en Agregar y, a continuación, seleccione el controlador que desee en la lista Controladores ODBC instalados y elija Aceptar.
En el cuadro de diálogo Configuración de ODBC, establezca los valores de las opciones conforme sea necesario y elija Aceptar.
Para obtener información acerca de cómo configurar un origen de datos específico del controlador elegido, elija el botón Ayuda en el cuadro de diálogo Configuración de ODBC.
Instalar orígenes de datos ODBC
Puede obtener soporte para Conectividad abierta de bases de datos (ODBC) si elige la opción de instalación Completa o Personalizada. Con ODBC, puede tener acceso a un origen de datos SQL Server desde Visual FoxPro; sin embargo, antes de tener acceso al origen de datos, deberá definirlo.
Para definir un origen de datos
Cambie al Panel de control de Windows y elija el icono ODBC.
En el cuadro de diálogo Orígenes de datos, elija Agregar.
En el cuadro de diálogo Agregar origen de datos, seleccione el controlador ODBC SQL Server y elija Aceptar.
En el cuadro de diálogo Instalación de ODBC SQL Server, escriba el nombre, la descripción y cualquier otra información del origen de datos y, a continuación, elija Aceptar.
En el cuadro de diálogo Orígenes de datos, elija Cerrar.
lunes, 19 de diciembre de 2011
INTRODUCCIÓN A LAS HERRAMIENTAS CASE
1. Introducción.
Las Herramientas case es la mejor base para el proceso de análisis y desarrollo de software, así que las computadoras afectan nuestras vidas nos guste o no. Utilizamos las maquinas en nuestra vida diaria, la mayor parte del tiempo sin reconocer conscientemente que estamos haciéndolo, a diario utilizamos aplicaciones domésticas como microondas, televisión, vídeo Casseteras o en la calle los cajeros automáticos, entre otros.
La verdad es que no podemos escapar de las computadoras. El rápido incremento es una hazaña de las computadoras junto al dramático decremento en tamaño y costo, y así esta tecnología, es una larga variedad de aplicaciones que éstas pueden soportar.
Desde el inicio de la escritura de software, ha existido un conocimiento de la necesidad de herramientas automatizadas para ayudar al diseñador del software. Inicialmente, la concentración estaba en herramientas de apoyo a programas como traductores, recopiladores, ensambladores, procesadores de macros, montadores y cargadores. Este conjunto de aplicaciones, aumentó de una manera rápida en un breve espacio de tiempo, causando una gran demanda por nuevo software a desarrollar. A medida que se escribía nuevo software, habían ya en existencia millones y millones de líneas de código que necesitaban se mantenidas y actualizadas.
Significado sigla CASE
Computer
Aided Assisted Automated
Software Systems
Engineering
2. Qué son las Herramientas CASE?
Se puede definir a las Herramientas CASE como un conjunto de programas y ayudas que dan asistencia a los analistas, ingenieros de software y desarrolladores, durante todos los pasos del Ciclo de Vida de desarrollo de un Software (Investigación Preliminar, Análisis, Diseño, Implementación e Instalación.).
CASE es también definido como el Conjunto de métodos, utilidades y técnicas que facilitan el mejoramiento del ciclo de vida del desarrollo de sistemas de información, completamente o en alguna de sus fases.
Se puede ver al CASE como la unión de las herramientas automáticas de software y las metodologías de desarrollo de software formales.
Existe también el CASE integrado que fue comenzando a tener un impacto muy Significativo en los negocios y sistemas de información de las organizaciones, además con este CASE integrado las compañías pueden desarrollar rápidamente sistemas de mejor calidad para soportar procesos críticos del negocio y asistir en el desarrollo y promoción intensiva de la información de productos y servicios.
*ERwin:
PLATINUM ERwin es una herramienta para el diseño de base de datos, que Brinda productividad en su diseño, generación, y mantenimiento de aplicaciones. Desde un modelo lógico de los requerimientos de información, hasta el modelo físico perfeccionado para las características específicas de la base de datos diseñada, además ERwin permite visualizar la estructura, los elementos importantes, y optimizar el diseño de la base de datos. Genera automáticamente las tablas y miles de líneas de stored procedure y triggers para los principales tipos de base de datos.
ERwin hace fácil el diseño de una base de datos. Los diseñadores de bases de datos sólo apuntan y pulsan un botón para crear un gráfico del modelo E-R (Entidad _ relación) de todos sus requerimientos de datos y capturar las reglas de negocio en un modelo lógico, mostrando todas las entidades, atributos, relaciones, y llaves importantes.
La migración automática garantiza la integridad referencial de la base de datos. ERwin establece una conexión entre una base de datos diseñada y una base de datos, permitiendo transferencia entre ambas y la aplicación de ingeniería reversa. Usando esta conexión, ERwin genera automáticamente tablas, vistas, índices, reglas de integridad referencial (llaves primarias, llaves foráneas), valores por defecto y restricciones de campos y dominios.
ERwin soporta principalmente bases de datos relacionales SQL y bases de datos que incluyen Oracle, Microsoft SQL Server, Sybase. El mismo modelo puede ser usado para generar múltiples bases de datos, o convertir una aplicación de una plataforma de base de datos a otra.
*PowerDesigner
PowerDesigner, la herramienta de modelamiento número uno de la industria, permite a las empresas, de manera más fácil, visualizar, analizar y manipular metadatos, logrando un efectiva arquitectura empresarial de información.
PowerDesigner para Arquitectura Empresarial también brinda un enfoque basado en modelos, el cual permite alinear al negocio con la tecnología de información, facilitando la implementación de arquitecturas efectivas de información empresarial. Brinda potentes técnicas de análisis, diseño y gestión de metadatos a la empresa.
PowerDesigner combina varias técnicas estándar de modelamiento con herramientas líder de desarrollo, como .NET, Sybase WorkSpace, Sybase Powerbuilder, Java y Eclipse, para darle a las empresas soluciones de análisis de negocio y de diseño formal de base de datos. Además trabaja con más de 60 bases de datos relacionales.
Las Herramientas case es la mejor base para el proceso de análisis y desarrollo de software, así que las computadoras afectan nuestras vidas nos guste o no. Utilizamos las maquinas en nuestra vida diaria, la mayor parte del tiempo sin reconocer conscientemente que estamos haciéndolo, a diario utilizamos aplicaciones domésticas como microondas, televisión, vídeo Casseteras o en la calle los cajeros automáticos, entre otros.
La verdad es que no podemos escapar de las computadoras. El rápido incremento es una hazaña de las computadoras junto al dramático decremento en tamaño y costo, y así esta tecnología, es una larga variedad de aplicaciones que éstas pueden soportar.
Desde el inicio de la escritura de software, ha existido un conocimiento de la necesidad de herramientas automatizadas para ayudar al diseñador del software. Inicialmente, la concentración estaba en herramientas de apoyo a programas como traductores, recopiladores, ensambladores, procesadores de macros, montadores y cargadores. Este conjunto de aplicaciones, aumentó de una manera rápida en un breve espacio de tiempo, causando una gran demanda por nuevo software a desarrollar. A medida que se escribía nuevo software, habían ya en existencia millones y millones de líneas de código que necesitaban se mantenidas y actualizadas.
Significado sigla CASE
Computer
Aided Assisted Automated
Software Systems
Engineering
2. Qué son las Herramientas CASE?
Se puede definir a las Herramientas CASE como un conjunto de programas y ayudas que dan asistencia a los analistas, ingenieros de software y desarrolladores, durante todos los pasos del Ciclo de Vida de desarrollo de un Software (Investigación Preliminar, Análisis, Diseño, Implementación e Instalación.).
CASE es también definido como el Conjunto de métodos, utilidades y técnicas que facilitan el mejoramiento del ciclo de vida del desarrollo de sistemas de información, completamente o en alguna de sus fases.
Se puede ver al CASE como la unión de las herramientas automáticas de software y las metodologías de desarrollo de software formales.
Existe también el CASE integrado que fue comenzando a tener un impacto muy Significativo en los negocios y sistemas de información de las organizaciones, además con este CASE integrado las compañías pueden desarrollar rápidamente sistemas de mejor calidad para soportar procesos críticos del negocio y asistir en el desarrollo y promoción intensiva de la información de productos y servicios.
*ERwin:
PLATINUM ERwin es una herramienta para el diseño de base de datos, que Brinda productividad en su diseño, generación, y mantenimiento de aplicaciones. Desde un modelo lógico de los requerimientos de información, hasta el modelo físico perfeccionado para las características específicas de la base de datos diseñada, además ERwin permite visualizar la estructura, los elementos importantes, y optimizar el diseño de la base de datos. Genera automáticamente las tablas y miles de líneas de stored procedure y triggers para los principales tipos de base de datos.
ERwin hace fácil el diseño de una base de datos. Los diseñadores de bases de datos sólo apuntan y pulsan un botón para crear un gráfico del modelo E-R (Entidad _ relación) de todos sus requerimientos de datos y capturar las reglas de negocio en un modelo lógico, mostrando todas las entidades, atributos, relaciones, y llaves importantes.
La migración automática garantiza la integridad referencial de la base de datos. ERwin establece una conexión entre una base de datos diseñada y una base de datos, permitiendo transferencia entre ambas y la aplicación de ingeniería reversa. Usando esta conexión, ERwin genera automáticamente tablas, vistas, índices, reglas de integridad referencial (llaves primarias, llaves foráneas), valores por defecto y restricciones de campos y dominios.
ERwin soporta principalmente bases de datos relacionales SQL y bases de datos que incluyen Oracle, Microsoft SQL Server, Sybase. El mismo modelo puede ser usado para generar múltiples bases de datos, o convertir una aplicación de una plataforma de base de datos a otra.
*PowerDesigner
PowerDesigner, la herramienta de modelamiento número uno de la industria, permite a las empresas, de manera más fácil, visualizar, analizar y manipular metadatos, logrando un efectiva arquitectura empresarial de información.
PowerDesigner para Arquitectura Empresarial también brinda un enfoque basado en modelos, el cual permite alinear al negocio con la tecnología de información, facilitando la implementación de arquitecturas efectivas de información empresarial. Brinda potentes técnicas de análisis, diseño y gestión de metadatos a la empresa.
PowerDesigner combina varias técnicas estándar de modelamiento con herramientas líder de desarrollo, como .NET, Sybase WorkSpace, Sybase Powerbuilder, Java y Eclipse, para darle a las empresas soluciones de análisis de negocio y de diseño formal de base de datos. Además trabaja con más de 60 bases de datos relacionales.
domingo, 18 de diciembre de 2011
NORMALIZACIÓN II
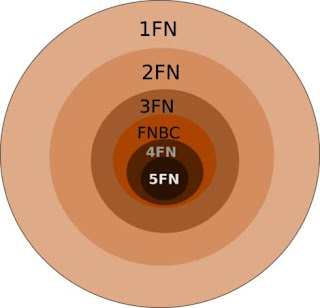
* Cuarta Forma Normal (4FN)
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X→→Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.
* Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si: • La tabla esta en 4FN • No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que esta en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
Una tabla se encuentra en 4FN si, y sólo si, para cada una de sus dependencias múltiples no funcionales X→→Y, siendo X una super-clave que, X es o una clave candidata o un conjunto de claves primarias.
* Quinta Forma Normal (5FN)
Una tabla se encuentra en 5FN si: • La tabla esta en 4FN • No existen relaciones de dependencias no triviales que no siguen los criterios de las claves. Una tabla que se encuentra en la 4FN se dice que esta en la 5FN si, y sólo si, cada relación de dependencia se encuentra definida por las claves candidatas.
NORMALIZACIÓN I
¿Qué es normalización?
Normalización es un proceso que clasifica relaciones, objetos, formas de relación y demás elementos en grupos, en base a las características que cada uno posee. Si se identifican ciertas reglas, se aplica un categoría; si se definen otras reglas, se aplicará otra categoría.
Estamos interesados en particular en la clasificación de las relaciones BDR. La forma de efectuar esto es a través de los tipos de dependencias que podemos determinar dentro de la relación. Cuando las reglas de clasificación sean más y más restrictivas, diremos que la relación está en una forma normal más elevada. La relación que está en la forma normal más elevada posible es que mejor se adapta a nuestras necesidades debido a que optimiza las condiciones que son de importancia para nosotros:
• La cantidad de espacio requerido para almacenar los datos es la menor
posible;
• La facilidad para actualizar la relación es la mayor posible;
• La explicación de la base de datos es la más sencilla posible.
Normalización es un proceso que clasifica relaciones, objetos, formas de relación y demás elementos en grupos, en base a las características que cada uno posee. Si se identifican ciertas reglas, se aplica un categoría; si se definen otras reglas, se aplicará otra categoría.
Estamos interesados en particular en la clasificación de las relaciones BDR. La forma de efectuar esto es a través de los tipos de dependencias que podemos determinar dentro de la relación. Cuando las reglas de clasificación sean más y más restrictivas, diremos que la relación está en una forma normal más elevada. La relación que está en la forma normal más elevada posible es que mejor se adapta a nuestras necesidades debido a que optimiza las condiciones que son de importancia para nosotros:
• La cantidad de espacio requerido para almacenar los datos es la menor
posible;
• La facilidad para actualizar la relación es la mayor posible;
• La explicación de la base de datos es la más sencilla posible.

TEORÍA DE NORMALIZACIÓN
Se aplica a los datos; con la finalidad de diseñar una base de datos más eficiente... Es un proceso que se basa en la descomposición aplicando las tres formas normales. 1FN, 2FN,·3FN.
En la 1FN , se busca eliminar los grupos repetitivos, logrando eliminar la redundancia de los datos
2FN, Todos los atributos deben depender completa y funcionalmente de la clave
3FN. Eliminar dependencias transitivas entre atributos no claves y eliminar campos que son resultados de càlculos de otros campos.
DICCIONARIO DE DATOS
Un diccionario de datos es un conjunto de metadatos que contiene las características lógicas y puntuales de los datos que se van a utilizar en el sistema que se programa, incluyendo nombre, descripción, alias, contenido y organización.
Identifica los procesos donde se emplean los datos y los sitios donde se necesita el acceso inmediato a la información, se desarrolla durante el análisis de flujo de datos y auxilia a los analistas que participan en la determinación de los requerimientos del sistema, su contenido también se emplea durante el diseño.
En un diccionario de datos se encuentra la lista de todos los elementos que forman parte del flujo de datos de todo el sistema. Los elementos mas importantes son flujos de datos, almacenes de datos y procesos. El diccionario de datos guarda los detalles y descripción de todos estos elementos.
PRIMERA FORMA NORMAL 1FN
Una tabla está en 1FN si sus atributos contienen valores atómicos. En el ejemplo, podemos ver que el atributo emails puede contener más de un valor, por lo que viola 1FN.
En general, tenemos una relación R con clave primaria K. Si un atributo M viola la condición de 1FN, tenemos dos opciones.
*Solución 1: duplicar los registros con valores repetidos
*Solución 2: separar el atributo que viola 1FN en una tabla
SEGUNDA FORMA NORMAL 2FN
Un esquema está en 2FN si:
Está en 1FN.
Todos sus atributos que no son de la clave principal tienen dependencia funcional completa respecto de todas las claves existentes en el esquema. En otras palabras, para determinar cada atributo no clave se necesita la clave primaria completa, no vale con una subclave.
La 2FN se aplica a las relaciones que tienen claves primarias compuestas por dos o más atributos. Si una relación está en 1FN y su clave primaria es simple (tiene un solo atributo), entonces también está en 2FN. Por tanto, de las soluciones anteriores, la tabla EMPLEADOS'(b) está en 1FN (y la tabla EMAILS no tiene atributos no clave), por lo que el esquema está en 2FN. Sin embargo, tenemos que examinar las dependencias funcionales de los atributos no clave de EMPLEADOS'(a). Las dependencias funcionales que tenemos son las siguientes:
nss->nombre, salario, email
puesto->salario
Como la clave es (nss, email), las dependencias de nombre, salario y email son incompletas, por lo que la relación no está en 2FN.
En general, tendremos que observar los atributos no clave que dependan de parte de la clave.
Para solucionar este problema, tenemos que hacer lo siguiente para los gupos de atributos con dependencia incompleta M:
Eliminar de R el atributo M.
Crear una nueva relación N con el atributo M y la parte de la clave primaria K de la que depende, que llamaremos K'.
La clave primaria de la nueva relación será K'.
TERCERA FORMA NORMAL 3FN
Una relación está en tercera forma normal si, y sólo si:
está en 2FN
y, además, cada atributo que no está incluido en la clave primaria no depende transitivamente de la clave primaria.
Por lo tanto, a partir de un esquema en 2FN, tenemos que buscar dependencias funcionales entre atributos que no estén en la clave.
En general, tenemos que buscar dependencias transitivas de la clave, es decir, secuencias de dependencias como la siguiente: K->A y A->B, donde A y B no pertenecen a la clave. La solución a este tipo de dependencias está en separar en una tabla adicional N el/los atributos B, y poner como clave primaria de N el atributo que define la transitividad A.
Siguiendo el ejemplo anterior, podemos detectar la siguiente transitividad:
nss->puesto
puesto->salario
En la 1FN , se busca eliminar los grupos repetitivos, logrando eliminar la redundancia de los datos
2FN, Todos los atributos deben depender completa y funcionalmente de la clave
3FN. Eliminar dependencias transitivas entre atributos no claves y eliminar campos que son resultados de càlculos de otros campos.
DICCIONARIO DE DATOS
Un diccionario de datos es un conjunto de metadatos que contiene las características lógicas y puntuales de los datos que se van a utilizar en el sistema que se programa, incluyendo nombre, descripción, alias, contenido y organización.
Identifica los procesos donde se emplean los datos y los sitios donde se necesita el acceso inmediato a la información, se desarrolla durante el análisis de flujo de datos y auxilia a los analistas que participan en la determinación de los requerimientos del sistema, su contenido también se emplea durante el diseño.
En un diccionario de datos se encuentra la lista de todos los elementos que forman parte del flujo de datos de todo el sistema. Los elementos mas importantes son flujos de datos, almacenes de datos y procesos. El diccionario de datos guarda los detalles y descripción de todos estos elementos.
PRIMERA FORMA NORMAL 1FN
Una tabla está en 1FN si sus atributos contienen valores atómicos. En el ejemplo, podemos ver que el atributo emails puede contener más de un valor, por lo que viola 1FN.
En general, tenemos una relación R con clave primaria K. Si un atributo M viola la condición de 1FN, tenemos dos opciones.
*Solución 1: duplicar los registros con valores repetidos
*Solución 2: separar el atributo que viola 1FN en una tabla
SEGUNDA FORMA NORMAL 2FN
Un esquema está en 2FN si:
Está en 1FN.
Todos sus atributos que no son de la clave principal tienen dependencia funcional completa respecto de todas las claves existentes en el esquema. En otras palabras, para determinar cada atributo no clave se necesita la clave primaria completa, no vale con una subclave.
La 2FN se aplica a las relaciones que tienen claves primarias compuestas por dos o más atributos. Si una relación está en 1FN y su clave primaria es simple (tiene un solo atributo), entonces también está en 2FN. Por tanto, de las soluciones anteriores, la tabla EMPLEADOS'(b) está en 1FN (y la tabla EMAILS no tiene atributos no clave), por lo que el esquema está en 2FN. Sin embargo, tenemos que examinar las dependencias funcionales de los atributos no clave de EMPLEADOS'(a). Las dependencias funcionales que tenemos son las siguientes:
nss->nombre, salario, email
puesto->salario
Como la clave es (nss, email), las dependencias de nombre, salario y email son incompletas, por lo que la relación no está en 2FN.
En general, tendremos que observar los atributos no clave que dependan de parte de la clave.
Para solucionar este problema, tenemos que hacer lo siguiente para los gupos de atributos con dependencia incompleta M:
Eliminar de R el atributo M.
Crear una nueva relación N con el atributo M y la parte de la clave primaria K de la que depende, que llamaremos K'.
La clave primaria de la nueva relación será K'.
TERCERA FORMA NORMAL 3FN
Una relación está en tercera forma normal si, y sólo si:
está en 2FN
y, además, cada atributo que no está incluido en la clave primaria no depende transitivamente de la clave primaria.
Por lo tanto, a partir de un esquema en 2FN, tenemos que buscar dependencias funcionales entre atributos que no estén en la clave.
En general, tenemos que buscar dependencias transitivas de la clave, es decir, secuencias de dependencias como la siguiente: K->A y A->B, donde A y B no pertenecen a la clave. La solución a este tipo de dependencias está en separar en una tabla adicional N el/los atributos B, y poner como clave primaria de N el atributo que define la transitividad A.
Siguiendo el ejemplo anterior, podemos detectar la siguiente transitividad:
nss->puesto
puesto->salario
MODELO DE DATOS
Un modelo de datos es un lenguaje orientado a describir una Base de Datos. Típicamente un modelo de datos permite describir:
Las estructuras de datos de la base: El tipo de los datos que hay en la base y la forma en que se relacionan.
Las restricciones de integridad: Un conjunto de condiciones que deben cumplir los datos para reflejar correctamente la realidad deseada.
Operaciones de manipulación de los datos: típicamente, operaciones de agregado, borrado, modificación y recuperación de los datos de la base.
Otro enfoque es pensar que un modelo de datos permite describir los elementos de la realidad que intervienen en un problema dado y la forma en que se relacionan esos elementos entre sí.
No hay que perder de vista que una Base de Datos siempre está orientada a resolver un problema determinado, por lo que los dos enfoques propuestos son necesarios en cualquier desarrollo de software.
*Una clasificación de los modelos de datos
Una opción bastante usada a la hora de clasificar los modelos de datos es hacerlo de acuerdo al nivel de abstracción que presentan:
-Modelos de Datos Conceptuales
Son los orientados a la descripción de estructuras de datos y restricciones de integridad. Se usan fundamentalmente durante la etapa de Análisis de un problema dado y están orientados a representar los elementos que intervienen en ese problema y sus relaciones. El ejemplo más típico es el Modelo Entidad-Relación.
-Modelos de Datos Lógicos
Son orientados a las operaciones más que a la descripción de una realidad. Usualmente están implementados en algún Manejador de Base de Datos. El ejemplo más típico es el Modelo Relacional, que cuenta con la particularidad de contar también con buenas características conceptuales (Normalización de bases de datos).
-Modelos de Datos Físicos
Son estructuras de datos a bajo nivel implementadas dentro del propio manejador. Ejemplos típicos de estas estructuras son los Árboles B+, las estructuras de Hash, etc.
Las estructuras de datos de la base: El tipo de los datos que hay en la base y la forma en que se relacionan.
Las restricciones de integridad: Un conjunto de condiciones que deben cumplir los datos para reflejar correctamente la realidad deseada.
Operaciones de manipulación de los datos: típicamente, operaciones de agregado, borrado, modificación y recuperación de los datos de la base.
Otro enfoque es pensar que un modelo de datos permite describir los elementos de la realidad que intervienen en un problema dado y la forma en que se relacionan esos elementos entre sí.
No hay que perder de vista que una Base de Datos siempre está orientada a resolver un problema determinado, por lo que los dos enfoques propuestos son necesarios en cualquier desarrollo de software.
*Una clasificación de los modelos de datos
Una opción bastante usada a la hora de clasificar los modelos de datos es hacerlo de acuerdo al nivel de abstracción que presentan:
-Modelos de Datos Conceptuales
Son los orientados a la descripción de estructuras de datos y restricciones de integridad. Se usan fundamentalmente durante la etapa de Análisis de un problema dado y están orientados a representar los elementos que intervienen en ese problema y sus relaciones. El ejemplo más típico es el Modelo Entidad-Relación.
-Modelos de Datos Lógicos
Son orientados a las operaciones más que a la descripción de una realidad. Usualmente están implementados en algún Manejador de Base de Datos. El ejemplo más típico es el Modelo Relacional, que cuenta con la particularidad de contar también con buenas características conceptuales (Normalización de bases de datos).
-Modelos de Datos Físicos
Son estructuras de datos a bajo nivel implementadas dentro del propio manejador. Ejemplos típicos de estas estructuras son los Árboles B+, las estructuras de Hash, etc.
ATRIBUTOS Y DOMINIOS
DEFINICION DE ATRIBUTO
En bases de datos, un atributo representa una propiedad de interés de una entidad.
Los atributos se describen en la estructura de la base de datos empleando un modelo de datos.
Por ejemplo, se podría tener una entidad llamada "Alumno". Esta entidad puede estar constituida por uno o más atributos, que son propiedades de la entidad "Alumno" que interesan para almacenarse en la base de datos. Por ejemplo, la entidad "Alumno" podría tener los atributos: nombre, apellido, año de nacimiento, etc.
La elección de los atributos de una entidad depende del uso que se le dará a la base de datos. El alumno puede tener una "religión", pero si no interesa al fin de la base de datos, no es necesario almacenarla en un atributo.
En SQL un atributo es llamado columna.
DEFINICION DE DOMINIO
Un dominio describe un conjunto de posibles valores para cierto atributo. Como un dominio restringe los valores del atributo, puede ser considerado como una restricción. Matemáticamente, atribuir un dominio a un atributo significa "todos los valores de este atributo deben de ser elementos del conjunto especificado".
Distintos tipos de dominios son: enteros, cadenas de texto, fecha,no procedurales etc.
CARACTERISTICAS
Una base de datos relacional se compone de varias tablas o relaciones.
No pueden existir dos tablas con el mismo nombre ni registro.
Cada tabla es a su vez un conjunto de registros (filas y columnas).
La relación entre una tabla padre y un hijo se lleva a cabo por medio de las claves primarias y ajenas (o foráneas).
Las claves primarias son la clave principal de un registro dentro de una tabla y éstas deben cumplir con la integridad de datos.
Las claves ajenas se colocan en la tabla hija, contienen el mismo valor que la clave primaria del registro padre; por medio de éstas se hacen las relaciones.
En bases de datos, un atributo representa una propiedad de interés de una entidad.
Los atributos se describen en la estructura de la base de datos empleando un modelo de datos.
Por ejemplo, se podría tener una entidad llamada "Alumno". Esta entidad puede estar constituida por uno o más atributos, que son propiedades de la entidad "Alumno" que interesan para almacenarse en la base de datos. Por ejemplo, la entidad "Alumno" podría tener los atributos: nombre, apellido, año de nacimiento, etc.
La elección de los atributos de una entidad depende del uso que se le dará a la base de datos. El alumno puede tener una "religión", pero si no interesa al fin de la base de datos, no es necesario almacenarla en un atributo.
En SQL un atributo es llamado columna.
DEFINICION DE DOMINIO
Un dominio describe un conjunto de posibles valores para cierto atributo. Como un dominio restringe los valores del atributo, puede ser considerado como una restricción. Matemáticamente, atribuir un dominio a un atributo significa "todos los valores de este atributo deben de ser elementos del conjunto especificado".
Distintos tipos de dominios son: enteros, cadenas de texto, fecha,no procedurales etc.
CARACTERISTICAS
Una base de datos relacional se compone de varias tablas o relaciones.
No pueden existir dos tablas con el mismo nombre ni registro.
Cada tabla es a su vez un conjunto de registros (filas y columnas).
La relación entre una tabla padre y un hijo se lleva a cabo por medio de las claves primarias y ajenas (o foráneas).
Las claves primarias son la clave principal de un registro dentro de una tabla y éstas deben cumplir con la integridad de datos.
Las claves ajenas se colocan en la tabla hija, contienen el mismo valor que la clave primaria del registro padre; por medio de éstas se hacen las relaciones.
TEORÍA DE RELACIONES II
RECURSIVAS
Definición.
Hablamos de recursividad, tanto en el ámbito informático como en el ámbito matemático, cuando definimos algo (un tipo de objetos, una propiedad o una operación) en función de sí mismo. La recursividad en programación es una herramienta sencilla, muy útil y potente.
Tipos.
Podemos distinguir dos tipos de recursividad:
Directa: Cuando un subprograma se llama a si mismo una o mas veces directamente.
Indirecta: Cuando se definen una serie de subprogramas usándose unos a otros.
Características.
Un algoritmo recursivo consta de una parte recursiva, otra iterativa o no recursiva y una condición de terminación. La parte recursiva y la condición de terminación siempre existen. En cambio la parte no recursiva puede coincidir con la condición de terminación.
Algo muy importante a tener en cuenta cuando usemos la recursividad es que es necesario asegurarnos que llega un momento en que no hacemos más llamadas recursivas. Si no se cumple esta condición el programa no parará nunca.
ENTIDADES ASOCIATIVAS
La utilidad de una entidad asociativa consiste en que se puede interrelacionar con otras entidades y, de forma indirecta, nos permite tener interrelaciones en las que intervienen interrelaciones. Una entidad asociativa se denota recuadrando el rombo de la interrelación de la que proviene.
Ejemplo de entidad asociativa
La figura siguiente muestra un ejemplo de entidad asociativa:
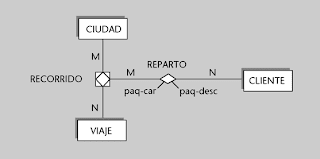
El mecanismo de las entidades asociativas subsume el de las entidades débiles
y resulta todavía más potente. Es decir, siempre que utilicemos una entidad débil podremos sustituirla por una entidad asociativa, pero no al revés.
3°DEPEMDENCIA FUNCIONAL
Una dependencia funcional es una conexión entre uno o más atributos. Por ejemplo si se conoce el valor de FechaDeNacimiento podemos conocer el valor de Edad.
Las dependencias funcionales del sistema se escriben utilizando una flecha, de la siguiente manera:
FechaDeNacimiento Edad
Aquí a FechaDeNacimiento se le conoce como un determinante. Se puede leer de dos formas FechaDeNacimiento determina a Edad o Edad es funcionalmente dependiente de FechaDeNacimiento. De la normalización (lógica) a la implementación (física o real) puede ser sugerible tener éstas dependencias funcionales para lograr la eficiencia en las tablas.

Definición.
Hablamos de recursividad, tanto en el ámbito informático como en el ámbito matemático, cuando definimos algo (un tipo de objetos, una propiedad o una operación) en función de sí mismo. La recursividad en programación es una herramienta sencilla, muy útil y potente.
Tipos.
Podemos distinguir dos tipos de recursividad:
Directa: Cuando un subprograma se llama a si mismo una o mas veces directamente.
Indirecta: Cuando se definen una serie de subprogramas usándose unos a otros.
Características.
Un algoritmo recursivo consta de una parte recursiva, otra iterativa o no recursiva y una condición de terminación. La parte recursiva y la condición de terminación siempre existen. En cambio la parte no recursiva puede coincidir con la condición de terminación.
Algo muy importante a tener en cuenta cuando usemos la recursividad es que es necesario asegurarnos que llega un momento en que no hacemos más llamadas recursivas. Si no se cumple esta condición el programa no parará nunca.
ENTIDADES ASOCIATIVAS
La utilidad de una entidad asociativa consiste en que se puede interrelacionar con otras entidades y, de forma indirecta, nos permite tener interrelaciones en las que intervienen interrelaciones. Una entidad asociativa se denota recuadrando el rombo de la interrelación de la que proviene.
Ejemplo de entidad asociativa
La figura siguiente muestra un ejemplo de entidad asociativa:

El mecanismo de las entidades asociativas subsume el de las entidades débiles
y resulta todavía más potente. Es decir, siempre que utilicemos una entidad débil podremos sustituirla por una entidad asociativa, pero no al revés.
3°DEPEMDENCIA FUNCIONAL
Una dependencia funcional es una conexión entre uno o más atributos. Por ejemplo si se conoce el valor de FechaDeNacimiento podemos conocer el valor de Edad.
Las dependencias funcionales del sistema se escriben utilizando una flecha, de la siguiente manera:
FechaDeNacimiento Edad
Aquí a FechaDeNacimiento se le conoce como un determinante. Se puede leer de dos formas FechaDeNacimiento determina a Edad o Edad es funcionalmente dependiente de FechaDeNacimiento. De la normalización (lógica) a la implementación (física o real) puede ser sugerible tener éstas dependencias funcionales para lograr la eficiencia en las tablas.

TEORÍA DE RELACIONES I
Relaciones
Las bases de datos representan entidades, que pueden ser objetos materiales como libros y fotografías, seres animados como personas o ideas abstractas como teorías y conceptos.
Para ser eficaces, las bases de datos deben representar a las entidades con la mayor fidelidad posible. Es por ello que los registros de las bases de datos deben incluir las propiedades más relevantes de cada tipo de entidad. Esto se hace a través de los modelos de registros que, como sabemos, se articulan en campos que, a su vez, corresponden a propiedades de las entidades. Si el modelo de registro descuida alguna propiedad importante de una entidad, la base de datos será ineficiente.
Ahora bien, las entidades, además de tener atributos, tienen relaciones entre ellas. Por ejemplo, supongamos una base de datos de imagen que contenga datos sobre fotografías y sobre fotógrafos. Ciertamente, tanto las fotografías como los fotógrafos son entidades que poseen determinadas propiedades, y los registros deben recogerlas de la forma más adecuada posible en sus modelos de registro, siempre según los objetivos de la base de datos y el público de la misma.
Ahora bien, por el mismo motivo que necesitamos representar a las entidades y a sus propiedades, necesitamos también representar las relaciones que se dan entre las entidades.
Por ejemplo, entre imágenes y autores se da la siguiente relación: las imágenes son hechas por autores. Para saber como tratar estas relaciones en una base de datos necesitamos determinar el grado de la misma. A efectos de su representación, consideramos que los grados de una relación pueden ser de tres clases:
- De uno a uno (1:1)
- De uno a varios (n:1)
- De varios a varios (n:m)
CARDINALIDAD
Cardinalidad de las relaciones
El tipo de cardinalidad se representa mediante una etiqueta en el exterior de la relación, respectivamente: "1:1", "1:N" y "N:M", aunque la notación depende del lenguaje utilizado, la que más se usa actualmente es el unificado. Otra forma de expresar la cardinalidad es situando un símbolo cerca de la línea que conecta una entidad con una relación:
"0" si cada instancia de la entidad no está obligada a participar en la relación.
"1" si toda instancia de la entidad está obligada a participar en la relación y, además, solamente participa una vez.
"N" , "M", ó "*" si cada instancia de la entidad no está obligada a participar en la relación y puede hacerlo cualquier número de veces.
Ejemplos de relaciones que expresan cardinalidad:
Cada esposo (entidad) está casado (relación) con una única esposa (entidad) y viceversa. Es una relación 1:1.
Una factura (entidad) se emite (relación) a una persona (entidad) y sólo una, pero una persona puede tener varias facturas emitidas a su nombre. Todas las facturas se emiten a nombre de alguien. Es una relación 1:N.
Un cliente (entidad) puede comprar (relación) varios artículos (entidad) y un artículo puede ser comprado por varios clientes distintos. Es una relación N:M.
TIPOS DE RELACIONES
1°DE UNO A UNO
Estas relaciones entre bases de datos se dan cuando cada campo clave aparece sólo una vez en cada una de las tablas.
Tomando un ejemplo del mundo real, una clara relación de "uno a uno" podría ser, el nombre de cualquier persona y su número de teléfono. Si partimosdel supuesto en que cada persona tiene un solo número de teléfono, se podría hablar de una relación "uno a uno".
Gráficamente, se podría representar de la siguiente manera:
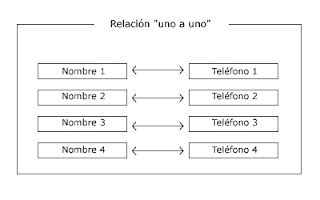
2°RELACION DE UNO A VARIOS
El ejemplo del caso anterior (cada persona, un teléfono), si bien es correcto teóricamente, es muy improbable desde el punto de vista de la realidad. Conla gran expansión de los teléfonos, por lo general, cada persona tiene un número de teléfono fijo, y ademas del teéfono móvil. Debemos tener en cuenta que de el de su casa también tendrá un número de teléfono de empresa, y que quizá también sus móviles estén divididos en ocio y trabajo.
Por ello, debemos tener nuestras bases de datos preparadas para ello. Este tipo de relaciones es conocido como "uno a varios", y se podría representar de la siguiente manera:
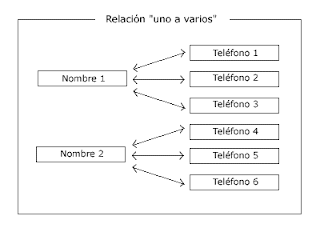
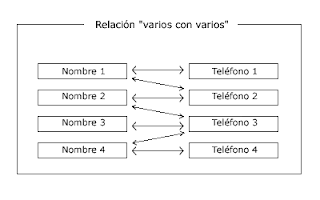
3°RELACION DE VARIOS A VARIOS
Cuando un registro de una tabla puede estar relacionado con más de un registro de la otra tabla y viceversa.
Por ejemplo: tenemos dos tablas una con los datos de clientes y otra con los artículos que se venden en la empresa, una cliente podrá realizar un pedido con varios artículos, y un artículo podrá ser vendido a más de un cliente.
Las relaciones varios a varios se suelen representar definiendo una tabla intermedia entre las dos tablas. Siguiendo el ejemplo anterior sería definir una tabla lineas de pedido relacionada con clientes y con artículos.
Las bases de datos representan entidades, que pueden ser objetos materiales como libros y fotografías, seres animados como personas o ideas abstractas como teorías y conceptos.
Para ser eficaces, las bases de datos deben representar a las entidades con la mayor fidelidad posible. Es por ello que los registros de las bases de datos deben incluir las propiedades más relevantes de cada tipo de entidad. Esto se hace a través de los modelos de registros que, como sabemos, se articulan en campos que, a su vez, corresponden a propiedades de las entidades. Si el modelo de registro descuida alguna propiedad importante de una entidad, la base de datos será ineficiente.
Ahora bien, las entidades, además de tener atributos, tienen relaciones entre ellas. Por ejemplo, supongamos una base de datos de imagen que contenga datos sobre fotografías y sobre fotógrafos. Ciertamente, tanto las fotografías como los fotógrafos son entidades que poseen determinadas propiedades, y los registros deben recogerlas de la forma más adecuada posible en sus modelos de registro, siempre según los objetivos de la base de datos y el público de la misma.
Ahora bien, por el mismo motivo que necesitamos representar a las entidades y a sus propiedades, necesitamos también representar las relaciones que se dan entre las entidades.
Por ejemplo, entre imágenes y autores se da la siguiente relación: las imágenes son hechas por autores. Para saber como tratar estas relaciones en una base de datos necesitamos determinar el grado de la misma. A efectos de su representación, consideramos que los grados de una relación pueden ser de tres clases:
- De uno a uno (1:1)
- De uno a varios (n:1)
- De varios a varios (n:m)
CARDINALIDAD
Cardinalidad de las relaciones
El tipo de cardinalidad se representa mediante una etiqueta en el exterior de la relación, respectivamente: "1:1", "1:N" y "N:M", aunque la notación depende del lenguaje utilizado, la que más se usa actualmente es el unificado. Otra forma de expresar la cardinalidad es situando un símbolo cerca de la línea que conecta una entidad con una relación:
"0" si cada instancia de la entidad no está obligada a participar en la relación.
"1" si toda instancia de la entidad está obligada a participar en la relación y, además, solamente participa una vez.
"N" , "M", ó "*" si cada instancia de la entidad no está obligada a participar en la relación y puede hacerlo cualquier número de veces.
Ejemplos de relaciones que expresan cardinalidad:
Cada esposo (entidad) está casado (relación) con una única esposa (entidad) y viceversa. Es una relación 1:1.
Una factura (entidad) se emite (relación) a una persona (entidad) y sólo una, pero una persona puede tener varias facturas emitidas a su nombre. Todas las facturas se emiten a nombre de alguien. Es una relación 1:N.
Un cliente (entidad) puede comprar (relación) varios artículos (entidad) y un artículo puede ser comprado por varios clientes distintos. Es una relación N:M.
TIPOS DE RELACIONES
1°DE UNO A UNO
Estas relaciones entre bases de datos se dan cuando cada campo clave aparece sólo una vez en cada una de las tablas.
Tomando un ejemplo del mundo real, una clara relación de "uno a uno" podría ser, el nombre de cualquier persona y su número de teléfono. Si partimosdel supuesto en que cada persona tiene un solo número de teléfono, se podría hablar de una relación "uno a uno".
Gráficamente, se podría representar de la siguiente manera:

2°RELACION DE UNO A VARIOS
El ejemplo del caso anterior (cada persona, un teléfono), si bien es correcto teóricamente, es muy improbable desde el punto de vista de la realidad. Conla gran expansión de los teléfonos, por lo general, cada persona tiene un número de teléfono fijo, y ademas del teéfono móvil. Debemos tener en cuenta que de el de su casa también tendrá un número de teléfono de empresa, y que quizá también sus móviles estén divididos en ocio y trabajo.
Por ello, debemos tener nuestras bases de datos preparadas para ello. Este tipo de relaciones es conocido como "uno a varios", y se podría representar de la siguiente manera:

3°RELACION DE VARIOS A VARIOS
Cuando un registro de una tabla puede estar relacionado con más de un registro de la otra tabla y viceversa.
Por ejemplo: tenemos dos tablas una con los datos de clientes y otra con los artículos que se venden en la empresa, una cliente podrá realizar un pedido con varios artículos, y un artículo podrá ser vendido a más de un cliente.
Las relaciones varios a varios se suelen representar definiendo una tabla intermedia entre las dos tablas. Siguiendo el ejemplo anterior sería definir una tabla lineas de pedido relacionada con clientes y con artículos.

lunes, 26 de septiembre de 2011
MODELO LOGICO
Modelos lógicos basados en objetos: los dos más extendidos son el modelo entidad-relación y el orientado a objetos. El modelo entidad-relación (E-R) se basa en una percepción del mundo compuesta por objetos, llamados entidades, y relaciones entre ellos. Las entidades se diferencian unas de otras a través de atributos. El orientado a objetos también se basa en objetos, los cuales contienen valores y métodos, entendidos como órdenes que actúan sobre los valores, en niveles de anidamiento. Los objetos se agrupan en clases, relacionándose mediante el envío de mensajes. Algunos autores definen estos modelos como "modelos semánticos".
domingo, 25 de septiembre de 2011
MODELO CONCEPTUAL
PROPÓSITO DE LA METODOLOGÍA DE DISEÑO
o El propósito de la metodología de diseño es facilitar el propósito de diseño y servir de soporte de la base de datos mediante la utilización de procedimientos, técnicas, herramientas ya ayudas para la generación de documentación.
OBJETIVO PRINCIPAL DEL DISEÑO CONCEPTUAL DE LA BASE DE DATOS
o El objetivo principal es construir un modelo conceptual de los datos de acuerdo con los requisitos de datos de la organización, enteramente independiente de los detalles de implementación. Y que sirvan de base para las demás etapas de diseño.
PASOS ASOCIADOS AL DISEÑO CONCEPTUAL DE LA BASE DE DATOS
* Los pasos asociados al diseño conceptual son:
1. Identificar los tipos de entidad.
2. Identificar los tipos de relación.
3. Identificar y asociar los atributos con los tipos de entidad y de relación.
4. Determinar los dominios de los atributos.
5. Determinar los atributos de clave candidata, principal y alternativa.
6. Considerar el uso de conceptos de modelado avanzados (opcional).
7. Comprobar si el modelo tiene redundancia.
8. Validar el modelo conceptual, comprobando las transacciones de los usuarios
9. Repasar el modelo de datos conceptual con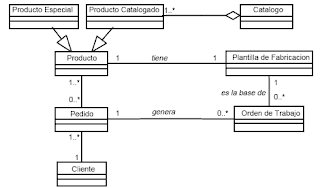 los usuarios.
los usuarios.
o El propósito de la metodología de diseño es facilitar el propósito de diseño y servir de soporte de la base de datos mediante la utilización de procedimientos, técnicas, herramientas ya ayudas para la generación de documentación.
OBJETIVO PRINCIPAL DEL DISEÑO CONCEPTUAL DE LA BASE DE DATOS
o El objetivo principal es construir un modelo conceptual de los datos de acuerdo con los requisitos de datos de la organización, enteramente independiente de los detalles de implementación. Y que sirvan de base para las demás etapas de diseño.
PASOS ASOCIADOS AL DISEÑO CONCEPTUAL DE LA BASE DE DATOS
* Los pasos asociados al diseño conceptual son:
1. Identificar los tipos de entidad.
2. Identificar los tipos de relación.
3. Identificar y asociar los atributos con los tipos de entidad y de relación.
4. Determinar los dominios de los atributos.
5. Determinar los atributos de clave candidata, principal y alternativa.
6. Considerar el uso de conceptos de modelado avanzados (opcional).
7. Comprobar si el modelo tiene redundancia.
8. Validar el modelo conceptual, comprobando las transacciones de los usuarios
9. Repasar el modelo de datos conceptual con
{kind=link}
 los usuarios.
los usuarios. MODELO ENTIDAD-RELACIÓN.
Denominado por sus siglas como: E-R; Este modelo representa a la realidad a través de entidades, que son objetos que existen y que se distinguen de otros por sus características, por ejemplo: un alumno se distingue de otro por sus características particulares como lo es el nombre, o el número de control asignado al entrar a una institución educativa, así mismo, un empleado, una materia, etc. Las entidades pueden ser de dos tipos:
*Tangibles:
Son todos aquellos objetos físicos que podemos ver,
tocar o sentir.
*Intangibles:
Todos aquellos eventos u objetos conceptuales que no
podemos ver, aun sabiendo que existen, por ejemplo:
la entidad materia, sabemos que existe, sin embargo, no la
podemos visualizar o tocar.
• Las características de las entidades en base de datos se llaman atributos, por ejemplo el nombre, dirección teléfono, grado, grupo, etc. son atributos de la entidad alumno; Clave, número de seguro social, departamento, etc., son atributos de la entidad empleado. A su vez una entidad se puede asociar o relacionar con más entidades a través de relaciones.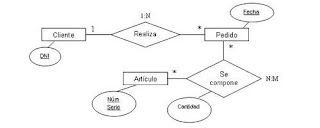
*Tangibles:
Son todos aquellos objetos físicos que podemos ver,
tocar o sentir.
*Intangibles:
Todos aquellos eventos u objetos conceptuales que no
podemos ver, aun sabiendo que existen, por ejemplo:
la entidad materia, sabemos que existe, sin embargo, no la
podemos visualizar o tocar.
• Las características de las entidades en base de datos se llaman atributos, por ejemplo el nombre, dirección teléfono, grado, grupo, etc. son atributos de la entidad alumno; Clave, número de seguro social, departamento, etc., son atributos de la entidad empleado. A su vez una entidad se puede asociar o relacionar con más entidades a través de relaciones.

ESTRUCTURA DE UNA BASE DE DATOS
Una base de datos, a fin de ordenar la información de manera lógica, posee un orden que debe ser cumplido para acceder a la información de manera coherente. Cada base de datos contiene una o más tablas, que cumplen la función de contener los campos.
En el siguiente ejemplo mostramos una tabla “comentarios” que contiene 4 campos.
Por consiguiente una base de datos posee el siguiente orden jerárquico:
• Tablas
• Campos
• Registros
• Lenguaje SQL
En el siguiente ejemplo mostramos una tabla “comentarios” que contiene 4 campos.
Por consiguiente una base de datos posee el siguiente orden jerárquico:
• Tablas
• Campos
• Registros
• Lenguaje SQL
sábado, 24 de septiembre de 2011
1°ARCHIVOS
Archivo:
Colección de registros almacenados siguiendo una estructura homogénea.
Base de datos:
Es una colección de archivos interrelacionados, son creados con un DBMS. El contenido de una base de datos engloba a la información concerniente (almacenadas en archivos) de una organización, de tal manera que los datos estén disponibles para los usuarios, una finalidad de la base de datos es eliminar la redundancia o al menos minimizarla. Los tres componentes principales de un sistema de base de datos son el hardware, el software DBMS y los datos a manejar, así como el personal encargado del manejo del sistema.
Almacenar en un archivo, en el que cada registro contendría los campos o datos de nómina de cada
Empleado.
2°SYSTEMAS DE ARCHIVOS
(File System). En computación, un sistema de archivos es un método para el almacenamiento y organización de archivos de computadora y los datos que estos contienen, para hacer más fácil la tarea encontrarlos y accederlos. Los sistemas de archivos son usados en dispositivos de almacenamiento como discos duros y CD-ROM e involucran el mantenimiento de la localización física de los archivos.
Más formalmente, un sistema de archivos es un conjunto de tipo de datos abstractos que son implementados para el almacenamiento, la organización jerárquica, la manipulación, el acceso, el direccionamiento y la recuperación de datos. Los sistemas de archivos comparten mucho en común con la tecnología de las bases de datos.
En general, los sistemas operativos tienen su propio sistema de archivos. En ellos, los sistemas de archivos pueden ser representados de forma textual (ej.: el shell de DOS) o gráficamente (ej.: Explorador de archivos en Windows) utilizando un gestor de archivos.
El software del sistema de archivos se encarga de organizar los archivos (que suelen estar segmentados físicamente en pequeños bloques de pocos bytes) y directorios, manteniendo un registro de qué bloques pertenecen a qué archivos, qué bloques no se han utilizado y las direcciones físicas de cada bloque.
3°TIPOS DE ARCHIVOS
Los archivos pueden clasificarse en cuatro tipos básicos; que son: los archivos maestros, los archivos de transacciones, los archivos de control y los archivos de planeamiento. Esta clasificación dependerá de la relación lógica que tengan que tener los datos, para dar apoyo a la actividad de la organización.
*ARCHIVO MAESTRO
Un archivo maestro es un conjunto de registros que se refieren a algún aspecto importante de las actividades de una organización, como por ejemplo el archivo de VENDEDORES. Un archivo maestro también puede reflejar la historia de los eventos que afectan a una entidad determinada, como es en el caso de un archivo HISTÓRICO DE VENTAS. Otros ejemplos son los archivos maestros de: PLAN DE CUENTAS; BANCOS, NÓMINA DEL PERSONAL, CLIENTES, VENDEDORES, PRODUCTOS, PROVEEDORES, COMPETIDORES.
*ARCHIVO DE TRANSACCIONES.
Un archivo de transacciones es un archivo temporal que persigue básicamente dos propósitos; uno es el de acumular datos de eventos en el momento que ocurran, y el segundo propósito es el de actualizar los archivos maestros para reflejar los resultados de las transacciones actuales. En otras palabras, guardan información sobre los eventos que afectan a la organización y sobre los cuales se calculan datos; como es en el caso de los archivos de VENTAS, ORDENES DE PRODUCCIÓN o PAGO DE SALARIOS. Otros ejemplos de archivos de transacciones son los archivos de: REGISTROS CONTABLES, COSTOS, FACTURAS, PAGOS A RECIBIR, PROCESOS DE EXPORTACIÓN, CONSULTA DE CLIENTES, PEDIDOS DE CLIENTES Y PEDIDOS A PROVEEDORES.
*ARCHIVOS DE CONTROL.
Los archivos de control contienen datos de los archivos maestros y de transacciones, para permitir el análisis del desempeño de la organización. Estos archivos generan medidas de control de los negocios, como ser el VOLUMEN DE VENTA POR PRODUCTO, VOLUMEN DE VENTA POR VENDEDOR, VOLUMEN DE VENTA POR CLIENTE, COMPRAS POR PROVEEDOR, COSTO DE REPOSICIÓN.
*ARCHIVO DE PLANEAMIENTO.
Los archivos de planeamiento, contienen datos referentes a los niveles esperados de los datos existentes en los archivos maestros y de transacciones; como por ejemplo: PROGRAMA DE VENTAS, PROGRAMA DE COMPRAS, PROGRAMA DE PRODUCCIÓN; PRESUPUESTO FINANCIERO. Por lo tanto los datos existentes en un archivo de planeamiento provienen de los archivos maestros, de transacciones, y de control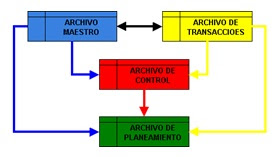
Colección de registros almacenados siguiendo una estructura homogénea.
Base de datos:
Es una colección de archivos interrelacionados, son creados con un DBMS. El contenido de una base de datos engloba a la información concerniente (almacenadas en archivos) de una organización, de tal manera que los datos estén disponibles para los usuarios, una finalidad de la base de datos es eliminar la redundancia o al menos minimizarla. Los tres componentes principales de un sistema de base de datos son el hardware, el software DBMS y los datos a manejar, así como el personal encargado del manejo del sistema.
Almacenar en un archivo, en el que cada registro contendría los campos o datos de nómina de cada
Empleado.
2°SYSTEMAS DE ARCHIVOS
(File System). En computación, un sistema de archivos es un método para el almacenamiento y organización de archivos de computadora y los datos que estos contienen, para hacer más fácil la tarea encontrarlos y accederlos. Los sistemas de archivos son usados en dispositivos de almacenamiento como discos duros y CD-ROM e involucran el mantenimiento de la localización física de los archivos.
Más formalmente, un sistema de archivos es un conjunto de tipo de datos abstractos que son implementados para el almacenamiento, la organización jerárquica, la manipulación, el acceso, el direccionamiento y la recuperación de datos. Los sistemas de archivos comparten mucho en común con la tecnología de las bases de datos.
En general, los sistemas operativos tienen su propio sistema de archivos. En ellos, los sistemas de archivos pueden ser representados de forma textual (ej.: el shell de DOS) o gráficamente (ej.: Explorador de archivos en Windows) utilizando un gestor de archivos.
El software del sistema de archivos se encarga de organizar los archivos (que suelen estar segmentados físicamente en pequeños bloques de pocos bytes) y directorios, manteniendo un registro de qué bloques pertenecen a qué archivos, qué bloques no se han utilizado y las direcciones físicas de cada bloque.
3°TIPOS DE ARCHIVOS
Los archivos pueden clasificarse en cuatro tipos básicos; que son: los archivos maestros, los archivos de transacciones, los archivos de control y los archivos de planeamiento. Esta clasificación dependerá de la relación lógica que tengan que tener los datos, para dar apoyo a la actividad de la organización.
*ARCHIVO MAESTRO
Un archivo maestro es un conjunto de registros que se refieren a algún aspecto importante de las actividades de una organización, como por ejemplo el archivo de VENDEDORES. Un archivo maestro también puede reflejar la historia de los eventos que afectan a una entidad determinada, como es en el caso de un archivo HISTÓRICO DE VENTAS. Otros ejemplos son los archivos maestros de: PLAN DE CUENTAS; BANCOS, NÓMINA DEL PERSONAL, CLIENTES, VENDEDORES, PRODUCTOS, PROVEEDORES, COMPETIDORES.
*ARCHIVO DE TRANSACCIONES.
Un archivo de transacciones es un archivo temporal que persigue básicamente dos propósitos; uno es el de acumular datos de eventos en el momento que ocurran, y el segundo propósito es el de actualizar los archivos maestros para reflejar los resultados de las transacciones actuales. En otras palabras, guardan información sobre los eventos que afectan a la organización y sobre los cuales se calculan datos; como es en el caso de los archivos de VENTAS, ORDENES DE PRODUCCIÓN o PAGO DE SALARIOS. Otros ejemplos de archivos de transacciones son los archivos de: REGISTROS CONTABLES, COSTOS, FACTURAS, PAGOS A RECIBIR, PROCESOS DE EXPORTACIÓN, CONSULTA DE CLIENTES, PEDIDOS DE CLIENTES Y PEDIDOS A PROVEEDORES.
*ARCHIVOS DE CONTROL.
Los archivos de control contienen datos de los archivos maestros y de transacciones, para permitir el análisis del desempeño de la organización. Estos archivos generan medidas de control de los negocios, como ser el VOLUMEN DE VENTA POR PRODUCTO, VOLUMEN DE VENTA POR VENDEDOR, VOLUMEN DE VENTA POR CLIENTE, COMPRAS POR PROVEEDOR, COSTO DE REPOSICIÓN.
*ARCHIVO DE PLANEAMIENTO.
Los archivos de planeamiento, contienen datos referentes a los niveles esperados de los datos existentes en los archivos maestros y de transacciones; como por ejemplo: PROGRAMA DE VENTAS, PROGRAMA DE COMPRAS, PROGRAMA DE PRODUCCIÓN; PRESUPUESTO FINANCIERO. Por lo tanto los datos existentes en un archivo de planeamiento provienen de los archivos maestros, de transacciones, y de control
LLAVE PRIMARIA O IDENTIFICADORA.
Cada instancia de una entidad debe ser unívocamente identificable, de manera tal que cada registro de la entidad debe estar separado y ser unívocamente identificable del resto de los registros de esa misma entidad; y quien permite esta identificación es la llave primaria. La llave primaria, que generalmente se identificada por medio de la letra @, puede ser un atributo o una combinación de atributos.
En consecuencia en cada archivo solo podrá existir un único registro que posea un valor determinado para su llave primaria. En otras palabras no puede existir en un archivo un registro que cuente con el mismo valor de otro registro en el campo de la llave primaria; la llave primaria no puede tener valores repetidos para distintos registros.
La llave primaria debe permitirle a un Sistema de Gestión de Base de Datos (SGBD), correctamente proyectado, generar un error si un usuario intenta incluir un nuevo registro cuya llave primaria coincida con la de otro registro ya existente en el archivo.
En el caso de la Base de Datos de compras, descripta anteriormente (ver 3.1.Estructura de una Base de datos), las llaves primarias de cada archivo son:
• ARCHIVO DE PRODUCTOS: @ Código artículo
• ARCHIVO DE PROVEEDORES: @ Código proveedor
• ARCHIVO ORIGEN DE LOS PRODUCTOS: @(Código proveedor + Código producto).
INDICES DE ACCESO
Un índice de acceso es un archivo auxiliar utilizado internamente por el SGDB para acceder directamente a cada registro del archivo de datos. La operación de indexación, creada por el SGDB, ordena a los registros de un archivo de datos de acuerdo con los campos utilizados como llave primaria e, incrementa sensiblemente la velocidad de ejecución de algunas operaciones sobre el archivo de datos. Normalmente para cada archivo de datos debe existir un índice cuya llave de indexación sea idéntica a su llave primaria. Este índice es llamado índice primario.
También es posible crear índices para un archivo de datos utilizando atributos (campos), o conjunto de atributos, diferentes de los de la llave primaria. Este tipo de índice, llamado índice secundario, es utilizado para reducir el tiempo de localización de una determinada información dentro de un archivo o para clasificar los registros del archivo de acuerdo con el orden necesario para la obtención de la información deseada.
Cada instancia de una entidad debe ser unívocamente identificable, de manera tal que cada registro de la entidad debe estar separado y ser unívocamente identificable del resto de los registros de esa misma entidad; y quien permite esta identificación es la llave primaria. La llave primaria, que generalmente se identificada por medio de la letra @, puede ser un atributo o una combinación de atributos.
En consecuencia en cada archivo solo podrá existir un único registro que posea un valor determinado para su llave primaria. En otras palabras no puede existir en un archivo un registro que cuente con el mismo valor de otro registro en el campo de la llave primaria; la llave primaria no puede tener valores repetidos para distintos registros.
La llave primaria debe permitirle a un Sistema de Gestión de Base de Datos (SGBD), correctamente proyectado, generar un error si un usuario intenta incluir un nuevo registro cuya llave primaria coincida con la de otro registro ya existente en el archivo.
En el caso de la Base de Datos de compras, descripta anteriormente (ver 3.1.Estructura de una Base de datos), las llaves primarias de cada archivo son:
• ARCHIVO DE PRODUCTOS: @ Código artículo
• ARCHIVO DE PROVEEDORES: @ Código proveedor
• ARCHIVO ORIGEN DE LOS PRODUCTOS: @(Código proveedor + Código producto).
INDICES DE ACCESO
Un índice de acceso es un archivo auxiliar utilizado internamente por el SGDB para acceder directamente a cada registro del archivo de datos. La operación de indexación, creada por el SGDB, ordena a los registros de un archivo de datos de acuerdo con los campos utilizados como llave primaria e, incrementa sensiblemente la velocidad de ejecución de algunas operaciones sobre el archivo de datos. Normalmente para cada archivo de datos debe existir un índice cuya llave de indexación sea idéntica a su llave primaria. Este índice es llamado índice primario.
También es posible crear índices para un archivo de datos utilizando atributos (campos), o conjunto de atributos, diferentes de los de la llave primaria. Este tipo de índice, llamado índice secundario, es utilizado para reducir el tiempo de localización de una determinada información dentro de un archivo o para clasificar los registros del archivo de acuerdo con el orden necesario para la obtención de la información deseada.
viernes, 23 de septiembre de 2011
5°DBMS
Los sistemas de gestión de bases de datos (en inglés database management system, abreviado DBMS) son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan.
El sistema manejador de bases de datos es la porción más importante del software de un sistema de base de datos. Un DBMS es una colección de numerosas rutinas de software interrelacionadas, cada una de las cuales es responsable de alguna tarea específica.
Las funciones principales de un DBMS son:
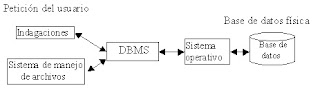
El sistema manejador de bases de datos es la porción más importante del software de un sistema de base de datos. Un DBMS es una colección de numerosas rutinas de software interrelacionadas, cada una de las cuales es responsable de alguna tarea específica.
Las funciones principales de un DBMS son:
- Crear y organizar la Base de datos.
- Establecer y mantener las trayectorias de acceso a la base
de datos de tal forma que los datos puedan ser accesados
rápidamente. - Manejar los datos de acuerdo a las peticiones de los usuarios.
Registrar el uso de las bases de datos. - Interacción con el manejador de archivos.
- Esto a través de las sentencias en DML al comando de el
sistema de archivos. Así el Manejador de base de datos es el
responsable del verdadero almacenamiento de los datos. - Respaldo y recuperación.
Consiste en contar con mecanismos implantados que
permitan la recuperación fácilmente de los datos en caso
de ocurrir fallas en el sistema de base de datos. - Control de concurrencia.
Consiste en controlar la interacción entre los usuarios
concurrentes para no afectar la inconsistencia de los datos. - Seguridad e integridad.
Consiste en contar con mecanismos que permitan el
control de la consistencia de los datos evitando que estos
se vean perjudicados por cambios no autorizados o previstos.
El DBMS es conocido también como Gestor de Base de datos.

La figura muestra el DBMS como interface entre la base de datos física y las peticiones del usuario. El DBMS interpreta las peticiones de entrada/salida del usuario y las manda al sistema operativo para la transferencia de datos entre la unidad de memoria secundaria y la memoria principal.
En sí, un sistema manejador de base de datos es el corazón de la base de datos ya que se encarga del control total de los posibles aspectos que la puedan afectar.
4°BASE DE DATOS
Características
Entre las principales características de los sistemas de base de datos podemos mencionar:
• Independencia lógica y física de los datos.
• Redundancia mínima.
• Acceso concurrente por parte de múltiples usuarios.
• Integridad de los datos.
• Consultas complejas optimizadas.
• Seguridad de acceso y auditoría.
• Respaldo y recuperación.
• Acceso a través de lenguajes de programación estándar.
Tipos de Base de Datos
Las bases de datos pueden clasificarse de varias maneras, de acuerdo al contexto que se esté manejando, la utilidad de las mismas o las necesidades que satisfagan.
Según la variabilidad de los datos almacenados
Bases de datos estáticas
Son bases de datos de sólo lectura, utilizadas primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones y tomar decisiones.
Bases de datos dinámicas
Éstas son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y adición de datos, además de las operaciones fundamentales de consulta. Un ejemplo de esto puede ser la base de datos utilizada en un sistema de información de un supermercado, una farmacia, un videoclub o una empresa.
Bases de datos bibliográficas
Sólo contienen un subrogante (representante) de la fuente primaria, que permite localizarla. Un registro típico de una base de datos bibliográfica contiene información sobre el autor, fecha de publicación, editorial, título, edición, de una determinada publicación, etc. Puede contener un resumen o extracto de la publicación original, pero nunca el texto completo, porque si no, estaríamos en presencia de una base de datos a texto completo (o de fuentes primarias —ver más abajo). Como su nombre lo indica, el contenido son cifras o números. Por ejemplo, una colección de resultados de análisis de laboratorio, entre otras.
Bases de datos de texto completo
Almacenan las fuentes primarias, como por ejemplo, todo el contenido de todas las ediciones de una colección de revistas científicas.
Entre las principales características de los sistemas de base de datos podemos mencionar:
• Independencia lógica y física de los datos.
• Redundancia mínima.
• Acceso concurrente por parte de múltiples usuarios.
• Integridad de los datos.
• Consultas complejas optimizadas.
• Seguridad de acceso y auditoría.
• Respaldo y recuperación.
• Acceso a través de lenguajes de programación estándar.
Tipos de Base de Datos
Las bases de datos pueden clasificarse de varias maneras, de acuerdo al contexto que se esté manejando, la utilidad de las mismas o las necesidades que satisfagan.
Según la variabilidad de los datos almacenados
Bases de datos estáticas
Son bases de datos de sólo lectura, utilizadas primordialmente para almacenar datos históricos que posteriormente se pueden utilizar para estudiar el comportamiento de un conjunto de datos a través del tiempo, realizar proyecciones y tomar decisiones.
Bases de datos dinámicas
Éstas son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y adición de datos, además de las operaciones fundamentales de consulta. Un ejemplo de esto puede ser la base de datos utilizada en un sistema de información de un supermercado, una farmacia, un videoclub o una empresa.
Bases de datos bibliográficas
Sólo contienen un subrogante (representante) de la fuente primaria, que permite localizarla. Un registro típico de una base de datos bibliográfica contiene información sobre el autor, fecha de publicación, editorial, título, edición, de una determinada publicación, etc. Puede contener un resumen o extracto de la publicación original, pero nunca el texto completo, porque si no, estaríamos en presencia de una base de datos a texto completo (o de fuentes primarias —ver más abajo). Como su nombre lo indica, el contenido son cifras o números. Por ejemplo, una colección de resultados de análisis de laboratorio, entre otras.
Bases de datos de texto completo
Almacenan las fuentes primarias, como por ejemplo, todo el contenido de todas las ediciones de una colección de revistas científicas.
3°MODELO DE BASE DATOS
Un modelo de base de datos o esquema de base de datos es la estructura o el formato de una base de datos, descrita en un lenguaje formal soportada por el sistema de gestión de bases de datos. En otras palabras, un "modelo de base de datos" es la aplicación de un modelo de datos usado en conjunción con un sistema de gestión de bases de datos.
Los esquemas generalmente son almacenados en un diccionario de datos. Aunque un esquema se defina en un lenguaje de base de datos de texto, el término a menudo es usado para referirse a una representación gráfica de la estructura de la base de datos.
Modelos comunes:
• Modelo jerárquico
• Modelo de red
• Modelo relacional
• Modelo entidad-relación
• Modelo objeto-relacional
• Modelo de objeto también define el conjunto de las operaciones que pueden ser realizadas sobre los datos. El modelo relacional, por ejemplo, define operaciones como selección, proyección y unión. Aunque estas operaciones pueden no ser explícitas en un lenguaje de consultas particular, proveen las bases sobre las que éstos son construidos.
En un modelo jerárquico, los datos son organizados en una estructura parecida a un árbol, implicando un eslabón solo ascendente en cada registro para describir anidar, y un campo de clase para guardar los registros en un orden particular en cada lista de mismo-nivel
Modelo de red
El modelo de red (definido por la especificación CODASYL) organiza datos que usan dos fundamental construcciones, registros llamados y conjuntos. Los registros contienen campos (que puede ser organizado jerárquicamente, como en el lenguaje COBOL de lenguaje de programación). Los conjuntos (para no ser confundido con conjuntos matemáticos) definen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier número de conjuntos, y un miembro en cualquier número de conjuntos.
Modelo Dimensional
El modelo dimensional es una adaptación especializada del modelo relacional, solía representar datos en depósitos de datos, en un camino que los datos fácilmente pueden ser resumidos usando consultas OLAP. En el modelo dimensional, una base de datos consiste en una mesa sola grande de los hechos que son descritos usando dimensiones y medidas. Una dimensión proporciona el contexto de un hecho (como quien participó, cuando y donde pasó, y su tipo) y es usado en preguntas al grupo hechos relacionados juntos. Las dimensiones tienden a ser discretas y son a menudo jerárquicas; por ejemplo, la posición (ubicación) podría incluir el edificio, el estado, y el país
Modelo de objeto
En años recientes, el paradigma mediante objetos ha sido aplicado a la tecnología de base de datos, creando un nuevo modelo de programa sabido (conocido) como bases de datos de objeto. Estas bases de datos intentan traer el mundo de base de datos y el uso que programa el mundo más cerca juntos, en particular por asegurando que la base de datos usa el mismo sistema de tipo que el programa de uso
2°TERMINOLIGIAS
En informática, o concretamente en el contexto de una base de datos relacional, un registro (también llamado fila o tupla) representa un objeto único de datos implícitamente estructurados en una tabla. En términos simples, una tabla de una base de datos puede imaginarse formada de filas y columnas o campos. Cada fila de una tabla representa un conjunto de datos relacionados, y todas las filas de la misma tabla tienen la misma estructura.
Un registro es un conjunto de campos que contienen los datos que pertenecen a una misma repetición de entidad. Se le asigna automáticamente un número consecutivo (número de registro) que en ocasiones es usado como índice aunque lo normal y práctico es asignarle a cada registro un campo clave para su búsqueda.
La estructura implícita de un registro y el significado de los valores de sus campos exige que dicho registro sea entendido como una sucesión de datos, uno en cada columna de la tabla. La fila se interpreta entonces como una variable relacional compuesta por un conjunto de tuplas, cada una de las cuales consta de dos ítems: el nombre de la columna relevante y el valor que esta fila provee para dicha columna.
Cada columna espera un valor de un tipo concreto.
Un registro es un conjunto de campos que contienen los datos que pertenecen a una misma repetición de entidad. Se le asigna automáticamente un número consecutivo (número de registro) que en ocasiones es usado como índice aunque lo normal y práctico es asignarle a cada registro un campo clave para su búsqueda.
La estructura implícita de un registro y el significado de los valores de sus campos exige que dicho registro sea entendido como una sucesión de datos, uno en cada columna de la tabla. La fila se interpreta entonces como una variable relacional compuesta por un conjunto de tuplas, cada una de las cuales consta de dos ítems: el nombre de la columna relevante y el valor que esta fila provee para dicha columna.
Cada columna espera un valor de un tipo concreto.
1°CONCEPTOS GENERALES DE BASE DE DATOS
Una base de datos o banco de datos (en ocasiones abreviada con la sigla BD o con la abreviatura b. d.) es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido, una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. En la actualidad, y debido al desarrollo tecnológico de campos como la informática y la electrónica, la mayoría de las bases de datos están en formato digital (electrónico), que ofrece un amplio rango de soluciones al problema de almacenar datos.
Existen programas denominados sistemas gestores de bases de datos abreviado (SGBD), que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas. También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental.
Existen programas denominados sistemas gestores de bases de datos abreviado (SGBD), que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas. También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental.
Suscribirse a:
Comentarios (Atom)